本文最后更新于:2023年9月25日 下午
kafka
Kafka是一个分布式流处理平台。它可以用于两大类别的应用:
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
kafka结构
Kafka作为一个集群,运行在一台或者多台服务器上。Kafka通过topic对存储的流数据进行分类。每个topic被划分为一个或多个partition,每个partition具有一个或多个副本。每条记录由topic-partition-offset唯一确定,其中包含一个key,一个value和一个timestamp.
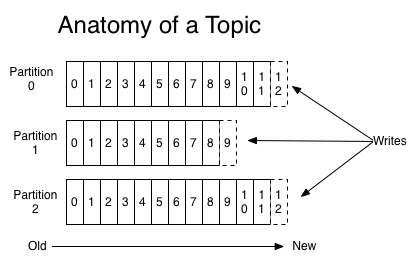
生产者可以将数据发布到所选择的topic中。消费者使用一个消费组名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例。消费者实例可以分布在多个进程中或者多个机器上。如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例(每一个partition在任意给定的时间内只能被每个订阅了这个topic的consumer组中的一个consumer消费。如果消费者多于分区数,会有消费者闲置)。如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
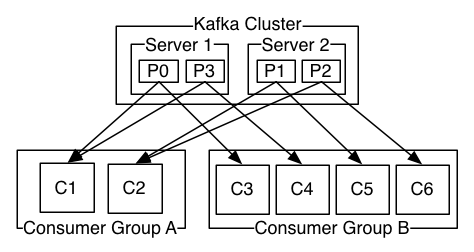
Kafka 只保证partition内的记录是有序的,而不保证topic中不同partition的顺序。
Kafka依赖Zookeeper:
- 管理 broker 与 consumer 的动态加入与离开。
- 当 broker 或 consumer 加入或离开时会触发负载均衡算法,使得一个 consumer group 内的多个 consumer 的消费负载平衡。
- 维护消费关系及每个 partition 的消费信息。
kafka生产消费流程
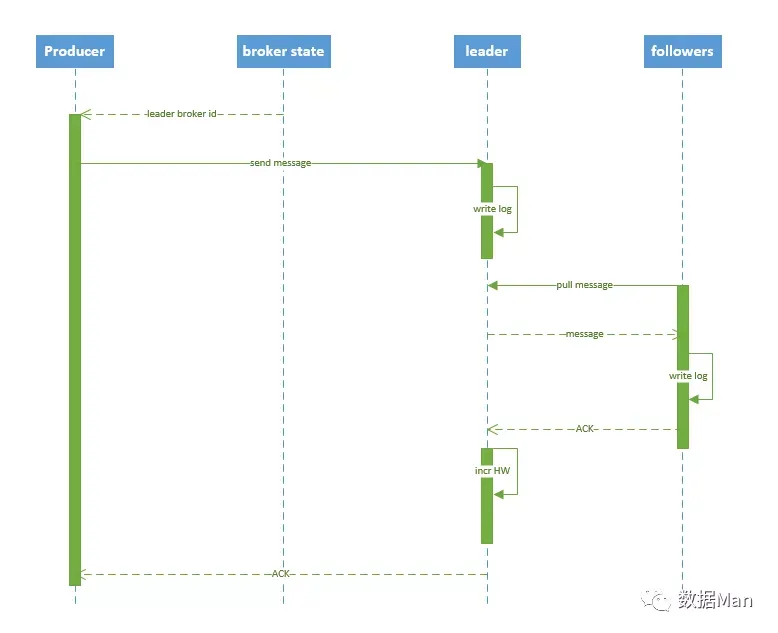
producer发送消息
- 封装为 ProducerRecord 实例
- 序列化
- 由 partitioner 确定具体分区
- 发送到内存缓冲区
- 由 producer 的一个专属 I/O 线程去取消息,并将其封装到一个批次 ,发送给对应分区的 kafka broker
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
consumer消费消息
- 连接 ZK 集群,拿到对应 topic 的 partition 信息和 partition 的 leader 的相关信息
- 连接到对应 leader 对应的 broker
- consumer 将自己保存的 offset 发送给 leader
- leader 根据 offset 等信息定位到 segment(索引文件和日志文件)
- 根据索引文件中的内容,定位到日志文件中该偏移量对应的开始位置读取相应长度的数据并返回给 consumer
安装
- 使用docker安装。先创建docker虚拟网络:
1
| docker network create app-tier --driver bridge
|
1
| docker run -d --name zookeeper-server --network app-tier -e ALLOW_ANONYMOUS_LOGIN=yes bitnami/zookeeper:latest
|
1
| docker run -d --network app-tier --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=zookeeper-server:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka
|
springboot中使用kafka进行生产消费
1
2
3
4
| <dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
spring.kafka.bootstrap-servers=127.0.0.1:9092
spring.kafka.producer.retries=0
spring.kafka.producer.acks=1
spring.kafka.producer.batch-size=16384
spring.kafka.producer.properties.linger.ms=0
spring.kafka.producer.buffer-memory = 33554432
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto.commit.interval.ms=1000
spring.kafka.consumer.auto-offset-reset=latest
spring.kafka.consumer.properties.session.timeout.ms=120000
spring.kafka.consumer.properties.request.timeout.ms=180000
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.listener.missing-topics-fatal=false
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Configuration
public class KafkaInitialConfiguration {
@Bean
public NewTopic initialTopic() {
return new NewTopic("testtopic",8, (short) 2 );
}
@Bean
public NewTopic updateTopic() {
return new NewTopic("testtopic",10, (short) 2 );
}
}
|
1
2
3
4
5
6
7
8
9
10
11
| @RestController
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/kafka/normal/{message}")
public void sendMessage1(@PathVariable("message") String normalMessage) {
kafkaTemplate.send("topic1", normalMessage);
}
}
|
1
2
3
4
5
6
7
8
| @Component
public class KafkaConsumer {
@KafkaListener(topics = {"topic1"})
public void onMessage1(ConsumerRecord<?, ?> record){
System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
|
get请求localhost:8080/kafka/normal/123,控制台打印
1
2
3
4
5
6
7
8
9
|
@KafkaListener(id = "consumer1",groupId = "felix-group",topicPartitions = {
@TopicPartition(topic = "topic1", partitions = { "0" }),
@TopicPartition(topic = "topic2", partitions = "0", partitionOffsets =
@PartitionOffset(partition = "1", initialOffset = "8"))
})
public void onMessage2(ConsumerRecord<?, ?> record) {
System.out.println("topic:"+record.topic()+"|partition:"+record.partition()+"|offset:"+record.offset()+"|value:"+record.value());
}
|
1
2
3
4
5
6
7
8
| @Component
public class KafkaConsumer {
@KafkaListener(id = "consumer2", groupId = "felix-group", topics = "topic1")
public void onMessage3(List<ConsumerRecord<?, ?>> records) {
System.out.println(">>>批量消费一次,records.size()=" + records.size());
records.forEach(System.out::println);
}
}
|
修改properties文件
1
2
3
4
|
spring.kafka.listener.type=batch
spring.kafka.consumer.max-poll-records=5
|
批量消费结果

为什么这里offset每次加2,不连续?
- 未使用事务时,at-least-once语义,消息重发时,会占用offset
- 使用事务时,每次事务的commit/abort,都会写一个标志,这个标志会占用offset
1
2
3
4
5
6
7
8
9
10
11
12
| @GetMapping("/kafka/callbackOne/{message}")
public void sendMessage2(@PathVariable("message") String callbackMessage) {
kafkaTemplate.send("topic1", callbackMessage).addCallback(success -> {
String topic = success.getRecordMetadata().topic();
int partition = success.getRecordMetadata().partition();
long offset = success.getRecordMetadata().offset();
System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);
}, failure -> {
System.out.println("发送消息失败:" + failure.getMessage());
});
}
|
先在application.propertise配置事务:
1
2
3
4
5
6
7
8
|
spring.kafka.producer.retries=1
spring.kafka.producer.transaction-id-prefix=tx_
spring.kafka.producer.properties.enable.idempotence=true
spring.kafka.producer.acks=all
|
1
2
3
4
5
6
7
8
| @GetMapping("/kafka/transaction")
public void sendMessage7() {
kafkaTemplate.executeInTransaction(operations -> {
operations.send("topic1", "test executeInTransaction");
throw new RuntimeException("fail");
});
}
|
事务回滚

1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Bean
public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() {
return (message, exception, consumer) -> {
System.out.println("消费异常:"+message.getPayload());
return null;
};
}
@KafkaListener(topics = {"topic1"},errorHandler = "consumerAwareErrorHandler")
public void onMessage4(ConsumerRecord<?, ?> record) throws Exception {
throw new Exception("简单消费-模拟异常");
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class CustomizePartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 1;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}
|
在application.propertise配置分区器:
1
| spring.kafka.producer.properties.partitioner.class=com.example.demo.CustomizePartitioner
|
消费结果
