Spark & Hive
本文最后更新于:2023年9月25日 下午
Spark
RDD
RDD是Spark对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体。
RDD与数组的简单对比:
| 对比项 | RDD | 数组 |
|---|---|---|
| 概念类型 | 数据模型抽象 | 数据结构实体 |
| 数据跨度 | 跨进程、跨计算节点 | 单机进程内 |
| 数据构成 | 数据分片(Partitions) | 数组元素 |
| 数据定位方式 | 数据分片索引 | 数组下标、索引 |
RDD具有四大属性:
- partitions:数据分片
- partitioner:分片切割规则
- dependencies:RDD依赖的上游RDD
- compute:转换函数
算子和延迟计算
在RDD的编程模型中,一共有两种算子,Transformations类算子和Actions类算子。开发者需要使用Transformations类算子,定义并描述数据形态的转换过程,然后调用Actions类算子,将计算结果收集起来、或是物化到磁盘。
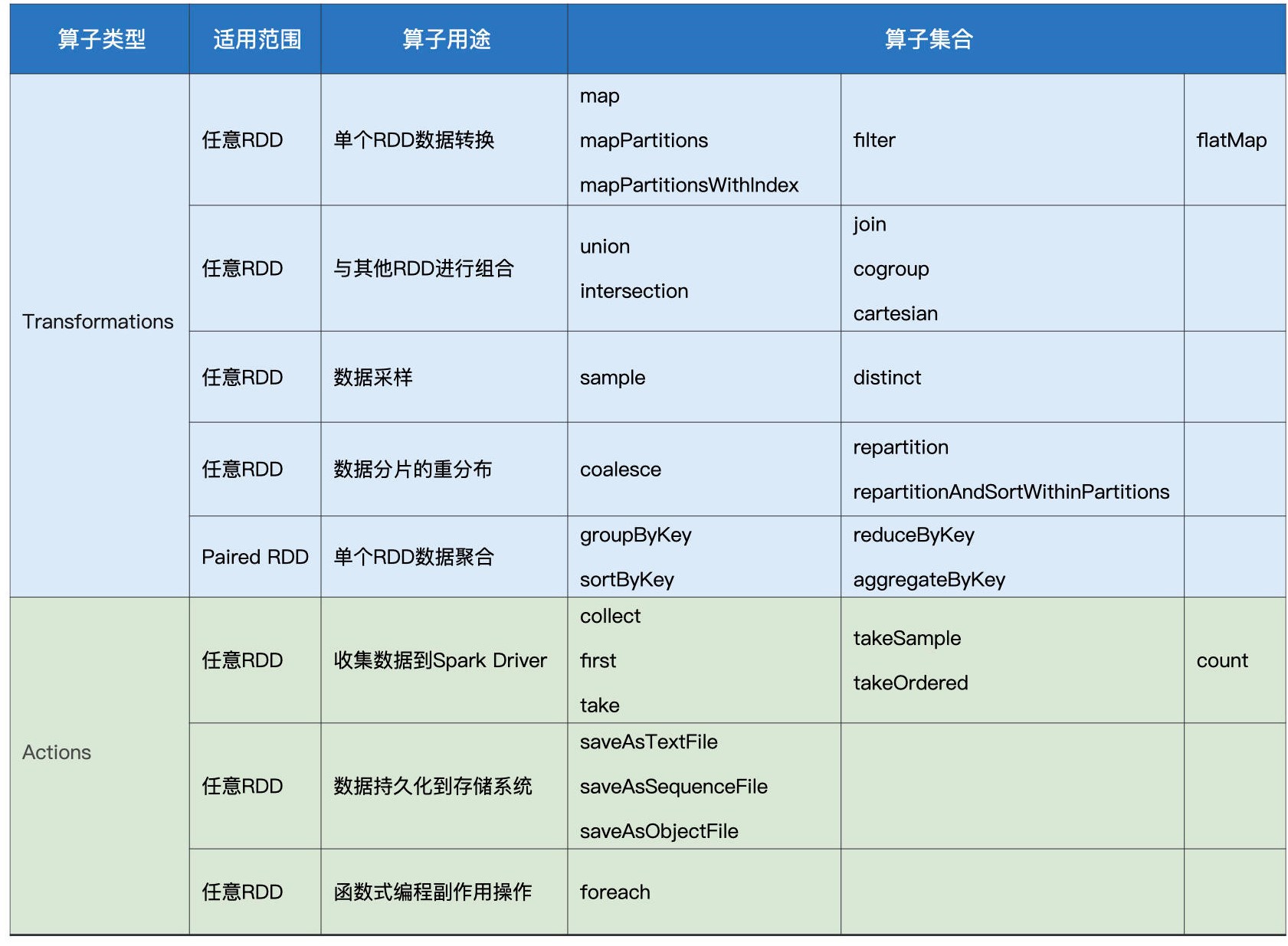
在这样的编程模型下,Spark在运行时的计算被划分为两个环节。
- 基于不同数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph,有向无环图);
- 通过Actions类算子,以回溯的方式去触发执行这个计算流图。

开发者调用的各类Transformations算子,仅用于构建计算流图,并不立即执行计算,当且仅当开发者调用Actions算子时,之前调用的转换算子才会付诸执行。因此成为“延迟计算”。
进程模型
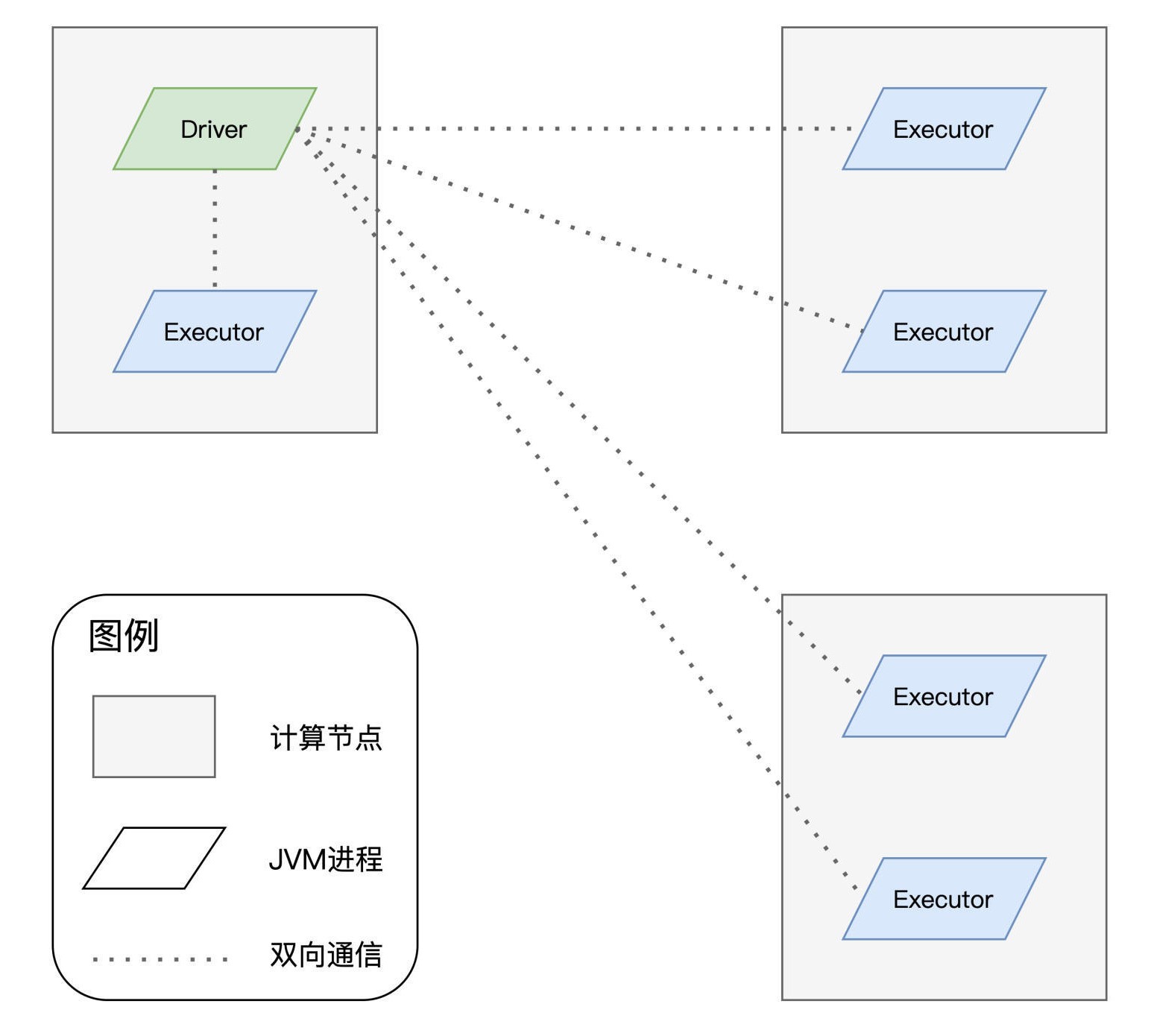
在Spark的应用开发中,任何一个应用程序的入口,都是带有SparkSession的main函数。SparkSession在提供Spark运行时上下文的同时(如调度系统、存储系统、内存管理、RPC通信),也可以为开发者提供创建、转换、计算分布式数据集(如RDD)的开发API。
在Spark分布式计算环境中,有且仅有一个JVM进程运行这样的main函数,叫作“Driver”。Driver最核心的作用在于,解析用户代码、构建计算流图,然后将计算流图转化为分布式任务,并把任务分发给集群中的执行进程“Executor”交付运行。
执行过程
以wordcount应用为例:
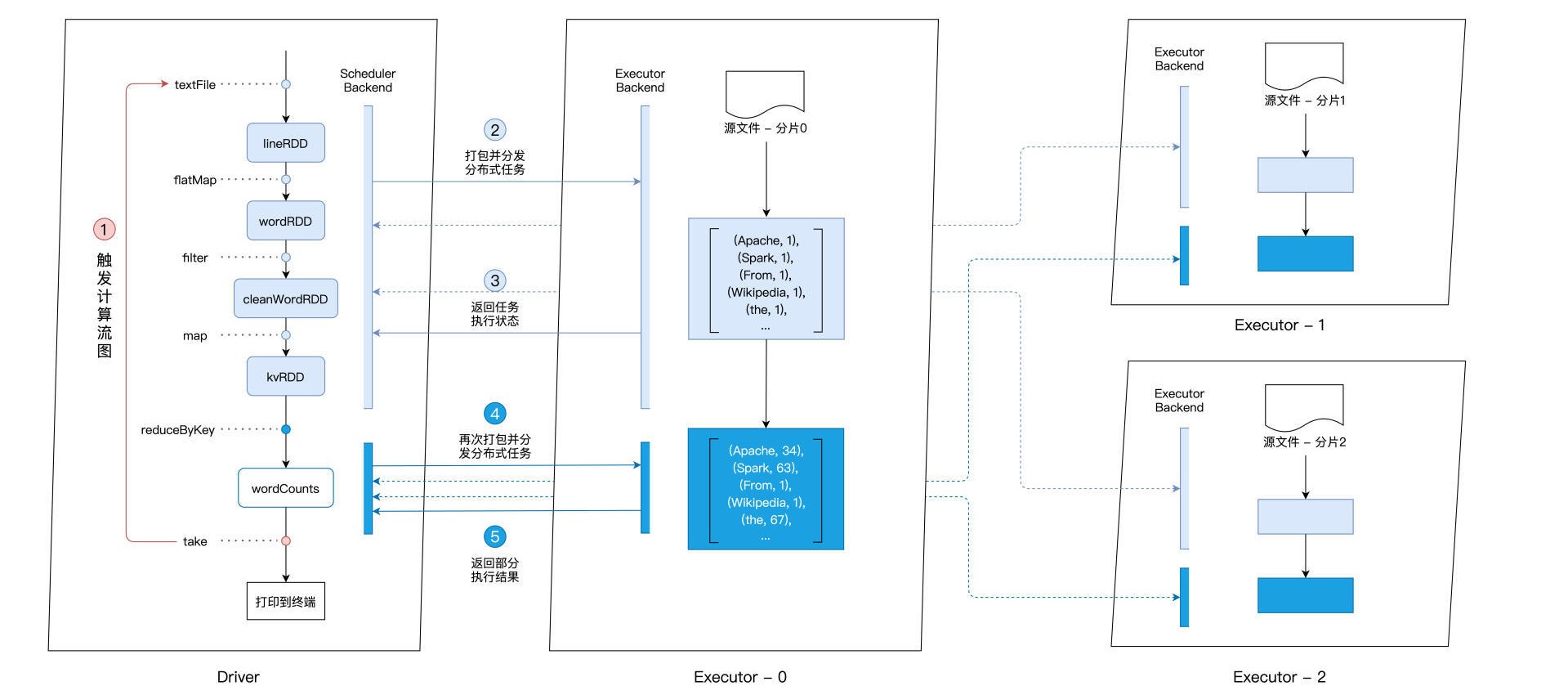
Driver通过take这个Action算子,来触发执行先前构建好的计算流图。沿着计算流图的执行方向,也就是图中从上到下的方向,Driver以Shuffle为边界创建、分发分布式任务。Shuffle表示的是集群范围内跨进程、跨节点的数据交换,如reduceByKey算子在执行前需要把相同单词分发到同一executor。
对于reduceByKey之前的所有操作,也就是textFile、flatMap、filter、map等,Driver会把它们“捏合”成一份任务,然后一次性地把这份任务打包、分发给每一个Executors。
三个Executors接收到任务之后,先是对任务进行解析,把任务拆解成textFile、flatMap、filter、map这4个步骤,然后分别对自己负责的数据分片进行处理。Executors会及时地向Driver汇报每个步骤的进展,从而方便Driver来统一协调下一步的工作。
任务调度
spark中有四个组件参与任务调度,分别是driver中的DAGScheduler,TaskScheduler和SchedulerBackend,和executor中的ExecutorBackend.
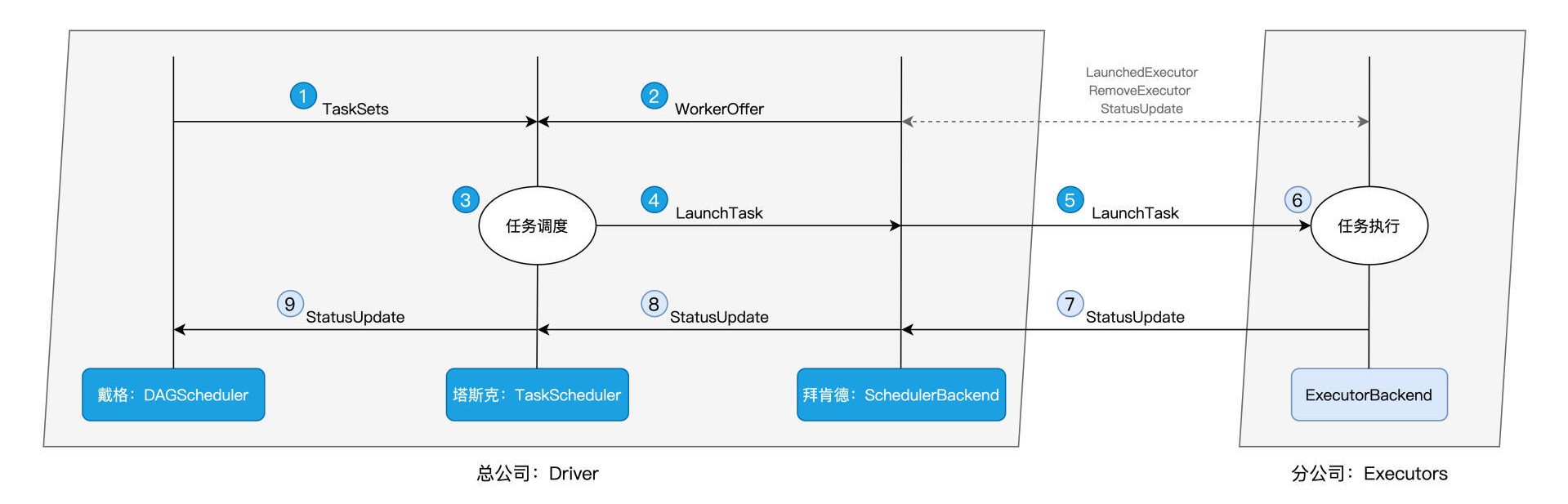
任务调度分为如下5个步骤:
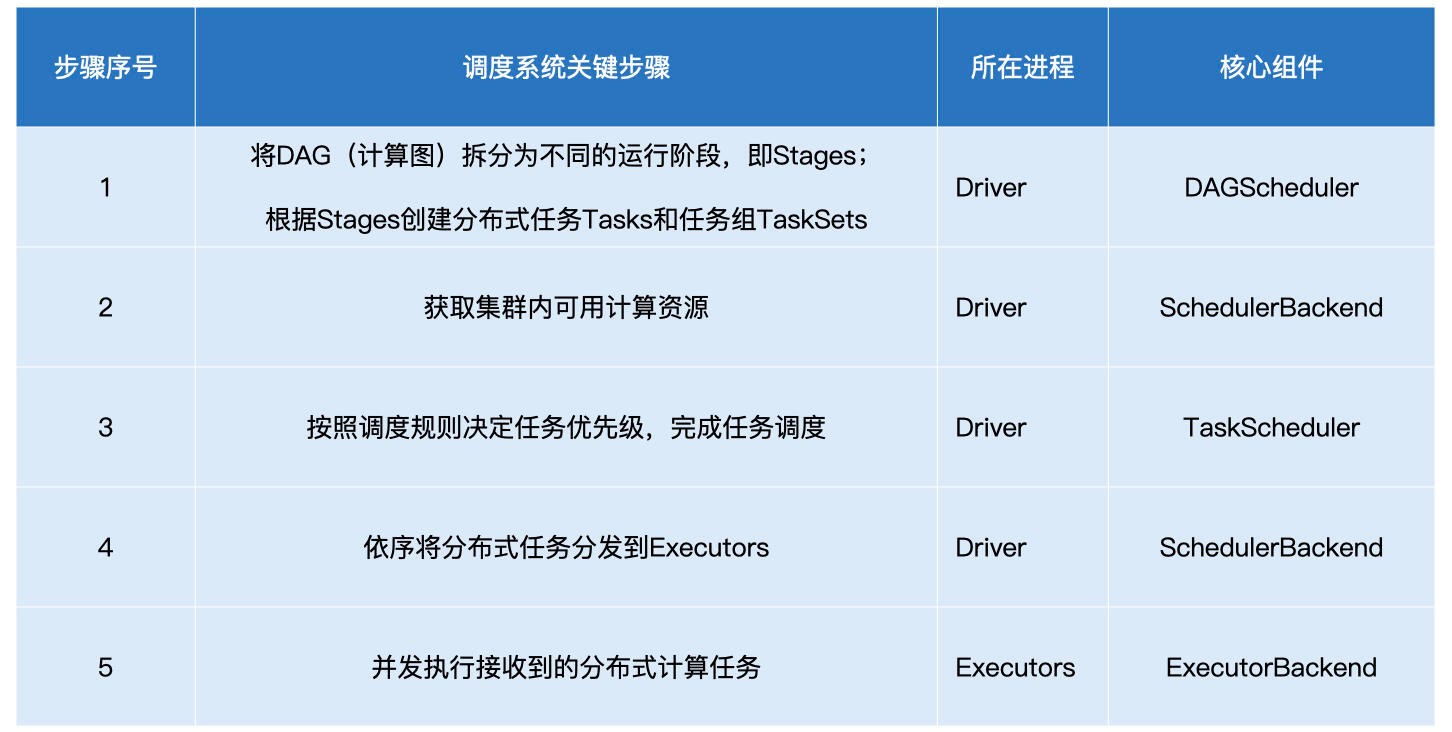
具体细节:
- DAGScheduler组件以Shuffle为边界,将开发者设计的计算图DAG拆分为多个执行阶段Stages,然后为每个Stage创建分布式任务Tasks和任务集TaskSet。
- SchedulerBackend组件通过与Executors中的ExecutorBackend组件的交互来实时地获取集群中可用的计算资源,并根据可用资源创建WorkerOffer(对可用资源的描述),以WorkerOffer为粒度提供计算资源。
- 对于给定WorkerOffer,TaskScheduler组件结合TaskSet中任务的本地性倾向,优先调度本地性倾向要求苛刻的Task。
- 被选中的Task由TaskScheduler传递给SchedulerBackend,再由SchedulerBackend分发到Executors中的ExecutorBackend。Executors接收到Task之后,即调用本地线程池来执行分布式任务。
DataFrame和SparkSQL
由于RDD的算子,如map、filter,它们都需要一个辅助函数f来作为形参,通过调用map(f)、filter(f)才能完成计算,Spark只知道开发者要做map、filter,但并不知道开发者打算怎么做map和filter。虽然自由度高,但缺乏优化空间。针对RDD优化空间受限的问题,Spark社区在1.3版本发布了DataFrame。
DataFrame与RDD一样,都是用来封装分布式数据集的。但DataFrame是携带数据模式(Schema)的结构化数据,而RDD是不携带Schema的分布式数据集。因此Spark才能有针对性地设计出更紧凑的数据结构,提升数据存储与访问效率。DataFrame定义了一套DSL算子(Domain Specific Language),如select、filter、agg、groupBy。
在RDD框架下开发的应用程序,会直接交付Spark Core运行。而使用DataFrame API开发的应用,则会先由Spark SQL优化过后再交由Spark Core去做执行。
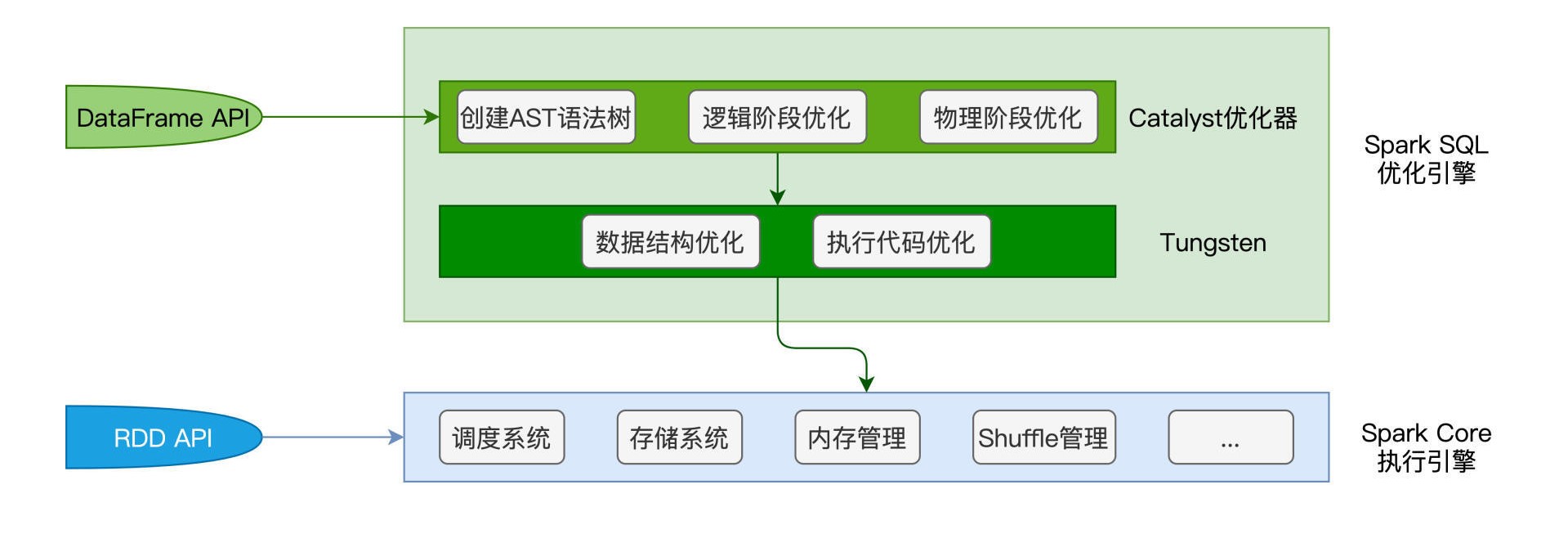
在Catalyst优化环节,Spark SQL首先把用户代码转换为AST语法树,又叫执行计划,然后分别通过逻辑优化和物理优化来调整执行计划。逻辑阶段的优化,主要通过先验的启发式经验,如谓词下推、列剪枝,对执行计划做优化调整。而物理阶段的优化,更多是利用统计信息,选择最佳的执行机制、或添加必要的计算节点。
Tungsten主要从数据结构和执行代码两个方面进一步优化。与默认的Java Object(org.apache.spark.sql.Row)相比,二进制的Unsafe Row以更加紧凑的方式来存储数据记录,大幅提升了数据的存储与访问效率。全阶段代码生成把多个算子融合为一个统一的函数,并将这个函数一次性地Apply到数据之上,相比不同算子的“链式调用”,消除了同一Stage内部不同算子之间的数据传递,这会显著提升计算效率。
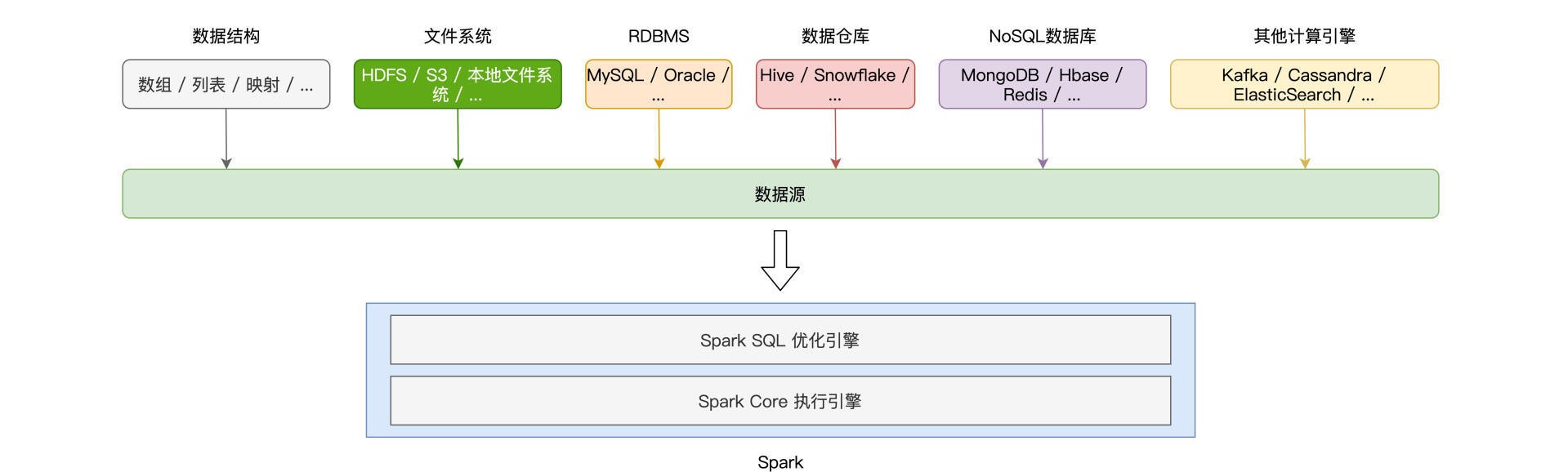
DataFrame可以从多种数据源创建:
HIVE
组成
Hive是Apache Hadoop社区用于构建数据仓库的核心组件,它负责提供种类丰富的用户接口,接收用户提交的SQL查询语句。这些查询语句经过Hive的解析与优化之后,往往会被转化为分布式任务,并交付Hadoop MapReduce付诸执行。它的核心部件,其实主要是User Interface(1)和Driver(3)。而不论是元数据库(4)、存储系统(5),还是计算引擎(6),Hive都以“外包”、“可插拔”的方式交给第三方独立组件,如下图所示。
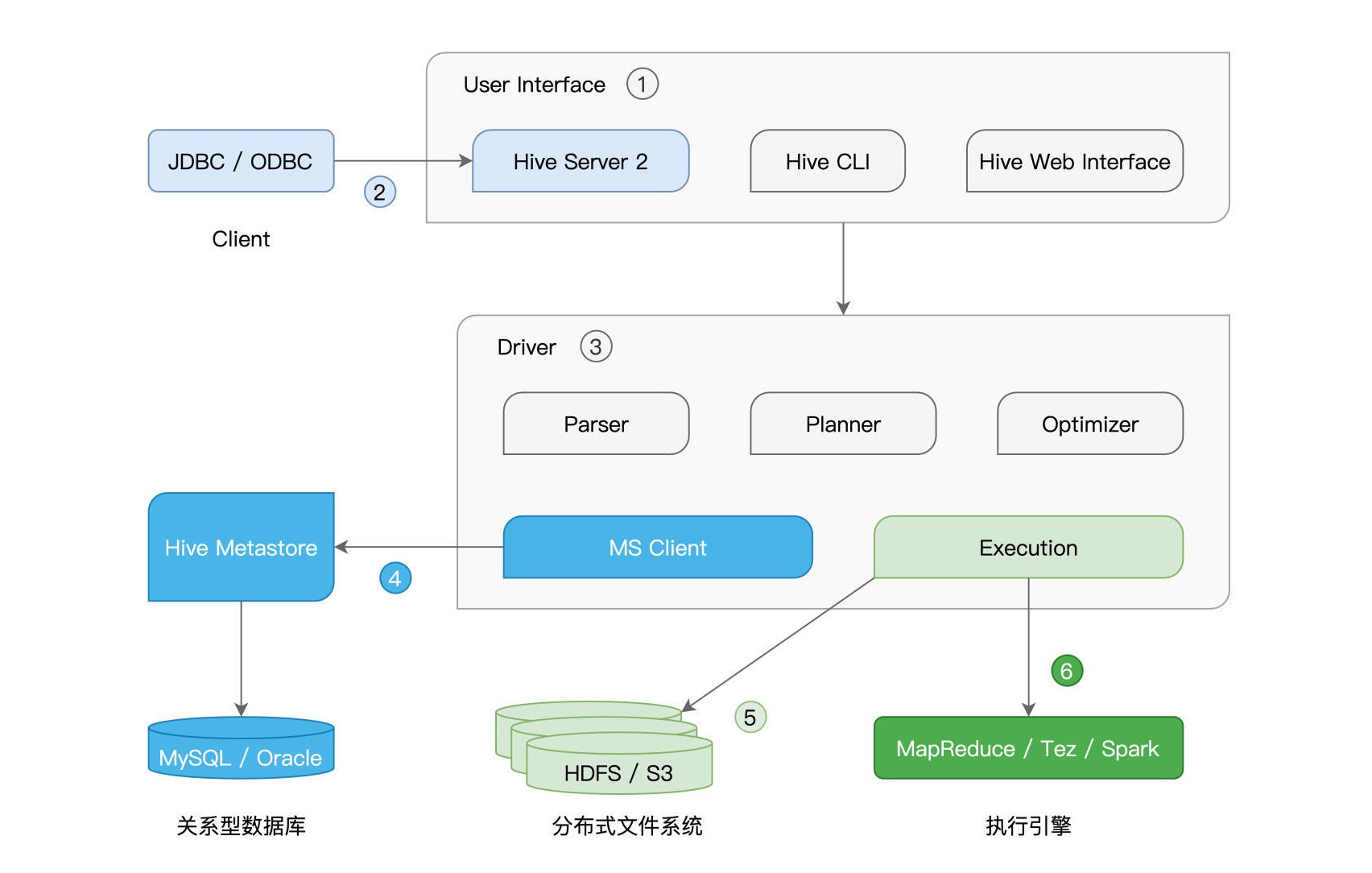
Hive的User Interface为开发者提供SQL接入服务,具体的接入途径有Hive Server 2(2)、CLI和Web Interface(Web界面入口)。
工作流程
接收到SQL查询之后,Hive的Driver首先使用其Parser组件,将查询语句转化为AST(抽象语法树)。
紧接着,Planner组件根据AST生成执行计划,而Optimizer则进一步优化执行计划。要完成这一系列的动作,Hive必须要能拿到相关数据表的元信息才行,比如表名、列名、字段类型、数据文件存储路径、文件格式,等等。而这些重要的元信息,通通存储在一个叫作“Hive Metastore”(4)的数据库中。
本质上,Hive Metastore其实就是一个普通的关系型数据库(RDBMS),可以是MySQL、Oracle等。实际上,除了用于辅助SQL语法解析、执行计划的生成与优化,Metastore的重要作用之一,是帮助底层计算引擎高效地定位并访问分布式文件系统中的数据源。
这里的分布式文件系统,可以是Hadoop生态的HDFS,也可以是云原生的Amazon S3。而在执行方面,Hive目前支持3类计算引擎,分别是Hadoop MapReduce、Tez和Spark。
当Hive采用Spark作为底层的计算引擎时,我们就把这种集成方式称作“Hive on Spark”。相反,当Spark仅仅是把Hive当成是一种元信息的管理工具时,我们把Spark与Hive的这种集成方式,叫作“Spark with Hive”。
Spark with Hive
以SparkSession + Hive Metastore为例。使用hive --service metastore命令来启动Hive Metastore.
假设Hive中有一张名为“salaries”的薪资表,每条数据都包含id和salary两个字段,表数据存储在HDFS,通过以下scala代码使用spark访问hive:
1 | |
Hive on Spark
在执行引擎方面,Hive默认搭载的是Hadoop MapReduce,但它同时也支持Tez和Spark。所谓的“Hive on Spark”,指的就是Hive采用Spark作为其后端的分布式执行引擎。执行引擎的切换对用户来说是完全透明的。
在Hive on Spark的集成方式中,Hive在将SQL语句转换为执行计划之后,还需要把执行计划“翻译”成RDD语义下的DAG,然后再把DAG交付给Spark Core付诸执行。在Hive on Spark这种集成模式下,Hive与Spark衔接的部分是Spark Core,而不是Spark SQL。而Spark SQL除了扮演数据分析子框架的角色之外,还是Spark新一代的优化引擎,因此Spark with Hive的集成在执行性能上会比Hive on Spark更好。
通过配置hive-site.xml来启用Hive on Spark: