MySQL性能
本文最后更新于:2023年9月25日 下午
MySQL
1. 存在更新,不存在插入-方案对比
1.1. REPLACE INTO
三种语法:
- REPLACE INTO tbl_name(col_name, …) VALUES(…);
- REPLACE INTO tbl_name(col_name, …) SELECT …;
- REPLACE INTO tbl_name SET col_name=value, …;
如果插入的行在唯一索引/主键上有重复,则删除原有的一条记录,并且插入一条新的记录来替换原记录。如果表不存在唯一索引/主键 或者 插入的数据唯一索引/主键没有重复的,那么会直接新增一条记录。
缺陷:
如果某个字段有默认值,在使用REPLACE INTO做数据修改时没有指定该字段,那么会将默认值的字段恢复到默认值,造成数据丢失。例如:role_id是主键,role_update_time具有默认值当前时间
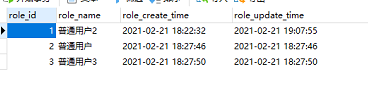
执行
REPLACE INTO role (role_id, role_name) VALUES(1, '普通用户4'),会使得role_id为1的列的role_update_time置为默认时间。如果使用了自增主键,被替换的记录的主键会被更新,这是因为其操作本质是先删除后插入。
删除重复记录时,会破坏索引,效率低。
并发时可能会造成死锁。
1.2. InsertOrUpdate(MySQL特有)
两种语法:
- INSERT INTO tbl_test(id,name,age,address) VALUES(1,’huahua1’,201,’京华市1’) ON DUPLICATE KEY UPDATE age = VALUES(age), address = VALUES(address);
- INSERT INTO table (a,b,c) VALUES(1,2,3) ON DUPLICATE KEY UPDATE c=c+1;
根据主键或唯一索引来判断当前插入是否已存在。记录已存在时,只会更新ON DUPLICATE KEY UPDATE之后指定的字段。如果同时传递了主键和唯一键,以主键为判断存在依据,唯一索引字段内容可以被修改。
如果是插入操作,affected_rows为1;如果更新操作,affected_rows为2;如果更新的数据和已有的数据一样(就相当于没变),affected_rows为0.
缺陷:
- InsertOrUpdate在更新数据时也会使AUTO_INCREMENT值加一,这样就会导致自增主键id不连续,并且增长很快。解决方案:拆分成两个动作,先更新,更新无效(返回值不大于0)再插入。
- 并发时可能会造成死锁。解决方案:先insert再捕获异常,然后进行更新;或使用insert ignore,然后判断update rows 是否是1,然后再决定是否更新。
1.3. 总结
REPLACE INTO可读性强,INSERT ... ON DUPLICATE KEY UPDATE ...可读性较差。REPLACE INTO会改变索引结构,因此效率较差;INSERT ... ON DUPLICATE KEY UPDATE ...会在原有基础上进行更新,性能更好一些。REPLACE INTO在未指定所有字段时,容易造成结果不符合预期(恢复默认值、自增主键会变)。
2. 普通索引和唯一索引-效率对比
2.1. 查询
假设执行select id from T where k=5这个查询语句。在索引树上查找的过程,先是通过B+树从树根开始,按层搜索到叶子节点,然后可以认为数据页内部通过二分法来定位记录。
- 对于普通索引来说,查找到满足条件的第一个记录(5,500)后,需要查找下一个记录,直到碰到第一个不满足k=5条件的记录。
- 对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索。
但由于InnoDB的数据是按数据页为单位来读写的,数据页在内存中检索速度很快,效率差异微乎其微。
2.2 更新
change buffer机制:当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
将change buffer中的操作应用到原数据页,得到最新结果的过程称为merge。除了访问这个数据页会触发merge外,系统有后台线程会定期merge。在数据库正常关闭(shutdown)的过程中,也会执行merge操作。
显然,如果能够将更新操作先记录在change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用buffer pool的,所以这种方式还能够避免占用内存,提高内存利用率。
- 对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。而这必须要将数据页读入内存。如果都已经读入到内存了,那直接更新内存会更快,就没必要使用change buffer了。
- 对于普通索引,如果数据页不在内存,则是将更新记录在change buffer,语句执行就结束了。
将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。