MySQL索引
本文最后更新于:2023年9月25日 下午
MySQL 索引
字符串索引方法
前缀索引
示例表:
1 | |
邮箱登录场景使用select f1, f2 from SUser where email='xxx';。
创建前缀索引alter table SUser add index index1(email);。与全字段索引相比,占用的空间更小,但会增加额外的记录扫描次数。因此需要定义好长度。
通过区分度确定前缀索引的长度:
1 | |
使用前缀索引可能会损失区分度,所以需要预先设定一个可以接受的损失比例,比如5%。然后,在返回的L4~L7中,找出不小于 L * 95%的值,选择最短的前缀。
此外,使用前缀索引就用不上覆盖索引对查询性能的优化了。
hash字段
添加hash字段及其索引:alter table t add id_card_crc int unsigned, add index(id_card_crc);。
每次插入新记录的时候,都同时用crc32()这个函数得到校验码填到这个新字段。
查询方法:select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'。
倒序存储
存放身份证等信息时,由于前缀区分度不高,但后缀区分度高,因此入库时使用倒序存储,再创建前缀索引。查询时使用select field_list from t where id_card = reverse('input_id_card_string');。
比较
- 直接创建完整索引,比较占用空间;
- 创建前缀索引,节省空间,但会增加查询扫描次数,并且不能使用覆盖索引;
- 字符串前缀区分度差时,使用倒序存储,再创建前缀索引。只支持等值查询;
- 创建hash字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描。
MySQL 选错索引
代价估计错误
示例表:
1 | |
并使用存储过程idata()往表t中插入10万行记录,取值按整数递增,即:(1,1,1),(2,2,2),(3,3,3) 直到(100000,100000,100000)。
执行查询语句,并查看慢查询日志:
1 | |
日志结果:
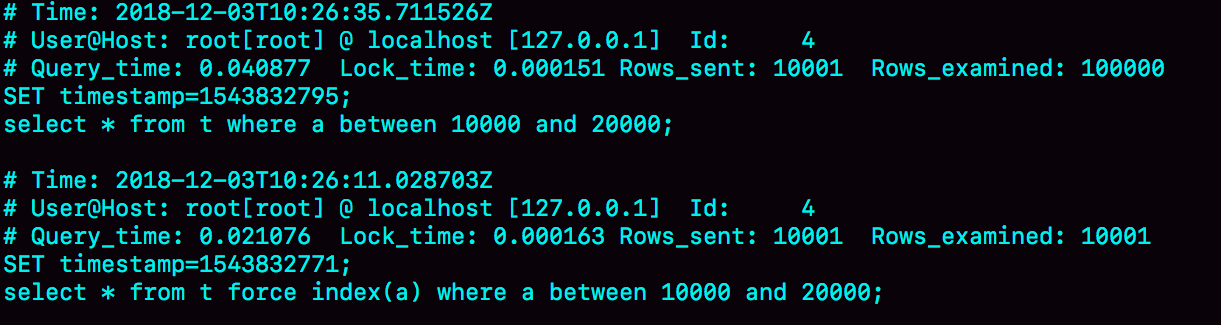
结果Q1扫描了10万行,显然是走了全表扫描,执行时间是40毫秒。Q2扫描了10001行,执行了21毫秒。也就是说,没有使用force index的时候,MySQL用错了索引,导致了更长的执行时间。
原因分析
优化器通过判断扫描行数,结合是否使用临时表、是否排序等因素进行综合选择索引。
MySQL在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。可以使用show index方法,看到一个索引的基数Cardinality,即一个索引上不同的值的个数:

MySQL的基数是基于采样统计的。采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
通过explain查看预估扫描行数rows:
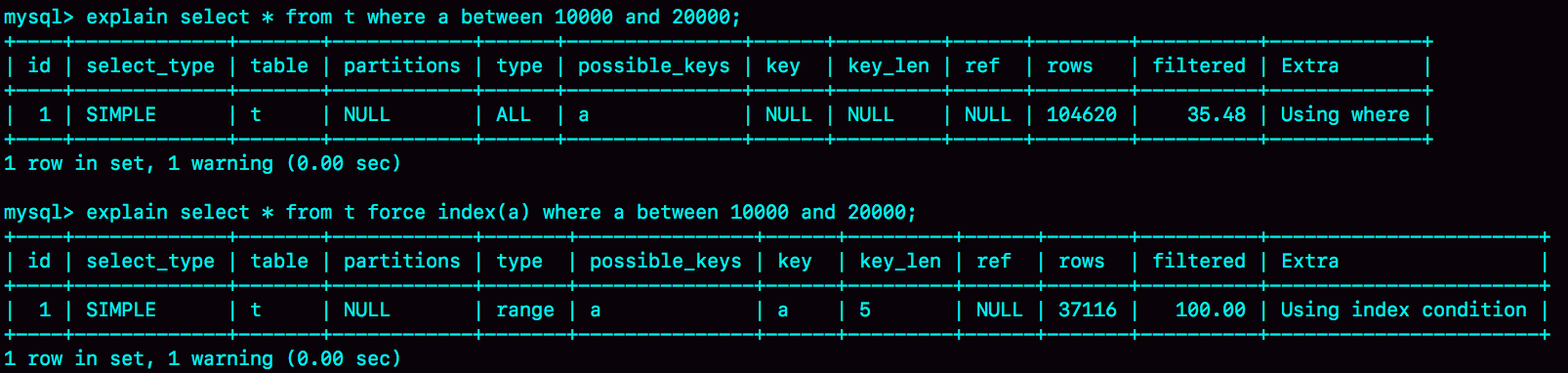
优化器为什么放着扫描37000行的执行计划不用,却选择了扫描行数是100000的执行计划呢?
原因:使用索引a需要回表,这个代价优化器也要算进去。
使用
force index,预估扫描行数为何估算错误?原因:delete 语句删掉了所有的数据,然后再通过call idata()插入了10万行数据。由于session A开启了事务并没有提交,之前的数据每一行数据都有两个版本,旧版本是delete之前的数据,新版本是标记为deleted的数据。这样,索引a上的数据其实就有两份。而如果没有使用
force index的语句,走主键,主键是直接按照表的行数来估计的。