Pointer_Analysis_Foundation
本文最后更新于:2023年9月25日 下午
Pointer_Analysis_Foundation
Pointer Analysis: Rules
上一篇笔记说到,在指针分析(PoinTer Analysis)中,我们关心的东西有两种:
可以用来构建指向关系的东西,即指针;
导致指向关系发生变化的语句。
在 PTA 完成之后,我们希望得到的东西是:每个指针的指向关系,即它们的 point-to set.
现在我们就来看看,在 PTA 里面有哪些规则。
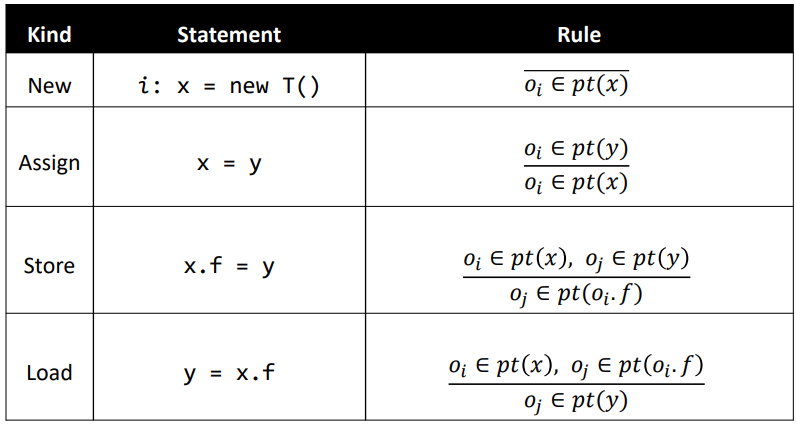
在这里,**pt(x) 代表指针 x 可能指向的 objects 的集合**,即 point-to set。横线上方代表前提,下方代表推论。如果前提为空,代表推论永远成立。如果你学过比如形式语义之类的课程,那么你应该对这种写法有所了解。
可能不是所有人都熟悉这个推导写法,用伪代码的角度来不严谨地表述,就是:
1 | |
但是,这并不代表我们跑一遍上面的代码就能得到 PTA 的结果,因为 PTA 是流不敏感的,每次 pt(x) 发生变动,我们就要根据规则刷新所有相关的指针。
所以你可以想象一下类似数据流分析那样的迭代式算法:我们确实可以把上面的代码一直不停地跑,直到所有的指针的 point-to set 都没有变化,算法停止。但是这不够有效率,我们会在接下来的学习中了解如何进行 PTA。
当然,也许有人更喜欢图表表示的方法:
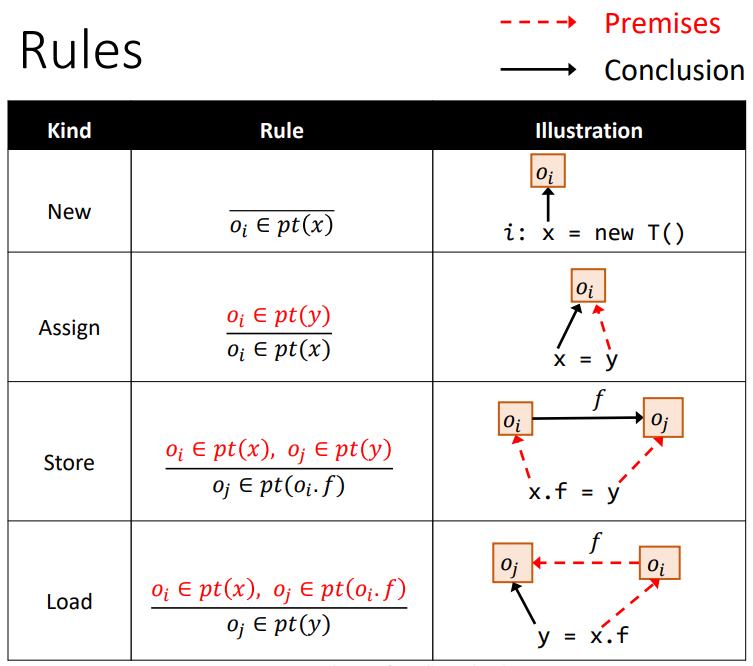
How to Implement Pointer Analysis
刚刚我们简单提到过,每次 pt(x) 发生变动,我们就要根据规则刷新所有和 x 相关的指针。
一个最暴力、最狗刨的办法就是一旦有指针的 point-to set 发生变动,就对整个程序重新跑一次所有规则。
但是我们已经知道,一个语句已经确定了指针的相关关系。我们可以根据程序构建一个图,表达这种关系。
例如 x = y; y = z;,我们可以依此画出一个 x <- y <- z 的链,一旦 pt(z) 发生变动,就沿着这条链去传播这种变动。这样就可以避免整个程序重新跑一次的繁琐了。
Pointer Flow Graph
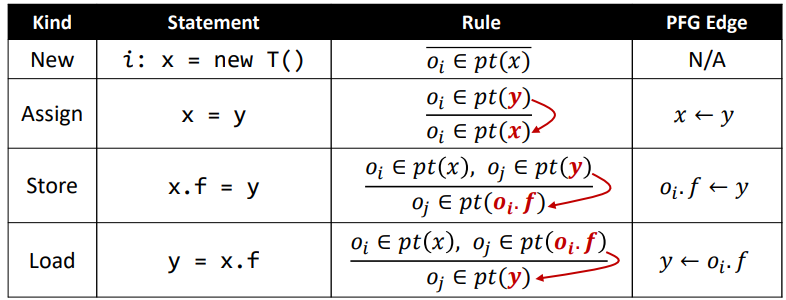
于是我们提出指针流图(PFG),在处理一个语句的时候,我们也在图上加上一条边,表达指针变动的传播对象。具体的加边规则如下:
举个例子:我们事先已经知道 $o_i\in pt(c),o_i\in pt(d)$,那么跑左边这样一段程序,我们会得到右边的 PFG:
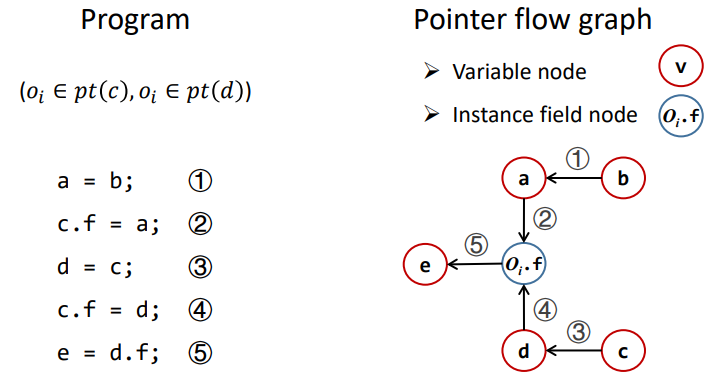
注意:我们尚未开始进行 objects 的传播,不要把「PFG 中各指针的指向关系」和「某个指针对 objects 的指向关系」混为一谈。
构建完了 PFG,现在假设我们有一条新的语句 j: b = new T(); 出现,那么我们不需要把这五行代码重新跑好几轮来更新 point-to set,而是只需要利用 PFG,将 $o_j$ 传递出去,也就是所谓的「求传递闭包」。
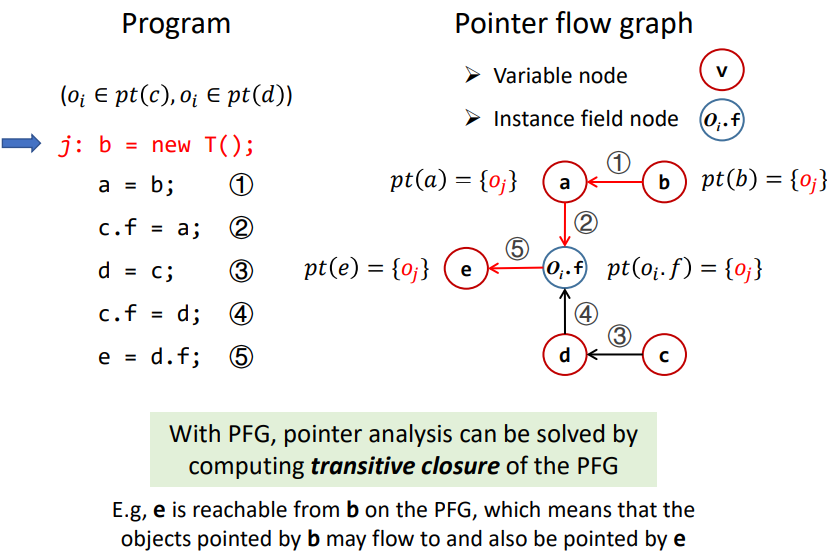
你可能发现了一个先有鸡还是先有蛋的问题:我们一开始就预设了 $o_i$ 属于谁,然后构建出了一个 PFG,然后通过 PFG 解决了 $o_j$ 属于谁的问题。但是如果我们是从零开始分析,那么我们又要如何「预设」呢?
因此 PTA 并不是一个「先做 PFG,再做指向关系分析」的过程,PFG 的构建和指向关系的更新是互相依赖的。我们需要在这种循环中来完成 PTA。
Pointer Analysis: Algorithms

这就是 PTA 的全部算法。注意到我们没有考虑调用,因此这是一个过程内分析的版本。
蓝色字已经标注出了我们关注的四类语句。
这一部分如果是从头学起,我们建议通过讲义和网课视频来进行学习,此处不再赘述。这里谈一谈如何对这个算法进行理解,以及大家在第一次学习时可能会出现的问题。
Why There?
首先,New 语句和 Assign 语句是只需要处理一次的。
New 语句相当于 object 的产生源头,不需要进行边的连接。
Assign 语句因为连接的是两个 variable,因此它们的连边也只需要进行一次。
因此这两个语句放在最开头,而不会进入 worklist 循环。
PTA 的 Worklist 算法基本上就是计算指针 point-to set 的变动,并将这种变动顺着 PFG 传播出去。
那么为什么我们要在 “n represents a variable x” 的时候去更新 Load 和 Store 呢?为什么 “n represents an instance field” 的时候,我们不需要去更新呢?
第一个问题,是因为
y = x.f并不代表x.f是一个变量,实际上我们访问的是 x 当时所指向的那个 object 的 field。因此,你可以理解为,每当pt(x)发生变化(例如新增了 $o_i$),那么实际上就是相当于扩充了程序的语句,新建了一个形如y = o_i.f的 Assign 语句。第二个问题,是因为我们在使用 instance field 的时候,不会直接拿来用,而是通过一个临时变量来存值。例如下面的例子,
y = x.f.g;在编译后会被拆成:1
2
3temp0 = x.f;
temp1 = temp0.g;
y = temp1;当
pt(o.f)发生变动,事实上就会将这个变动传播给temp0。当temp0发生变化,因为它是一个 variable,才继续更新其它语句。
Why They Work?
Worklist 的一个 entry <n, pts>,代表将 pts 并入 pt(n)。
因此 Propagate 是很好理解的,它就是将 point-to set 的变动传播的一个过程。
AddEdge 则除了在图上连接一条边之外,还会把 pt(source) 传给 pt(target)。
有的人可能会有疑问,这样子就可以实现完整的分析了吗?AddEdge 为什么要传 objects,明明 Assign 就已经把边做好了,我直接靠 New 引起的初始传播来求传递闭包不也行吗?
那么,考虑下面的代码:
1 | |
因为我们先建边,再跑 worklist,因此 pt(x) = {o_4} 确实可以顺着 PFG 传播,使得 pt(y) = {o_4}。这样看起来,AddEdge 的传播似乎真的没啥必要?
再考虑下面的代码:
1 | |
如果在 AddEdge 没有传 objects 的过程,那么上面的代码在 worklist 的第二轮执行就会仅单纯地加上 o_4.f <- x 这条 PFG 边,而不会将 $o_3$ 传给 $o_4.f$。因此,我们必须在连边的时候传 objects。
Pointer Analysis with Method Calls
当我们考虑过程间调用的时候,我们首先遇到的问题就是:某个调用语句指向了哪个被调用方法?
回忆一下,在 CHA 的视角下,我们如果想知道 y = x.m(...); 调用了哪个方法,会去看 x 的类型。但是此时,我们只能看到 T x = ...;,然后根据 T 的继承结构来推测 x 的可能类型,并连接所有可能的调用边,形成 call graph。
但是,有了指针分析,我们就没必要做得这么盲目了。我们现在能看到 i: T x = New U();,知道 pt(x) = {U o_i}。在 y = x.m(...);,我们就能直接找 U.m(),而不会去找所有可能的方法了。
对 Call 的处理规则如下:

它的伪代码解释:
1 | |
接下来我们逐步拆解每一步的含义。
找目标方法
get target method m by Dispatch(type(obj), k)
找目标方法的办法还是和 CHA 的差不多的。但是,在 CHA 中,我们直接获取变量的声明类型,然后对类型和方法签名做 dispatching。而现在我们是通过 object 的具体类型来做 dispatching 了。上面的伪代码用 type(obj) 使得 Dispatch() 的语义与 CHA 符合,帮助大家理解。

参数与返回值连边
1 | |
由于 Java 不支持参数默认值,因此调用填写的参数(arguments)和方法本身的参数(parameters)数量一定是相等的。因此,我们逐个将其连接起来,使得 point-to set 可以在过程间传递。
而对于返回值,请注意 Return 语句并不出现只有一个,所以 CFG 上所有的 return value 都会汇聚到 exit block 上。相比于 m_ret,在伪代码中我们用 m.exit 代表这个虚拟的指针,而实际的实现中我们会有一组 return variable,我们需要逐个将其连接到 r 上。
边的连接示意图如下:

this 变量的更新
add obj to pt(m.this)
参数和返回值的连边都是很容易想到的,但是为什么我们要进行 this 的更新呢?为什么我们不采用 add x -> m.this to PFG,而是采用 add obj to pt(m.this) 呢?
第一个问题,更新 this 是因为语言设计的需要,this 是类对实例的引用。例如,在上下文敏感的场景中,它能帮助区分对不同 object 的操作。
第二个问题,下图就可以很好地解释:

一个变量可能并不只指向一个对象,如果我们直接连接 x 到 this 上,就会把其它不同类的 object 传过来给 this。这显然是不合理的。
最后的完整算法

在新加入的算法中,AddReachable 负责维护已访问过的方法,并把被调用到的方法的语句S_m并入程序语句集 S 里。
由于方法与 object 的相关性,因此 Call 的处理模式和 Store, Load 一样,在 pt(x) 变动时,对整个程序的相关语句进行更新。
ProcessCall 中还针对 call graph 做了一点更细致的处理,如果同一个 call site l,l -> m 已经在 CG 里了,那么如果 m 没有发生变化,就不再连边。这是因为 l -> m 已存在,代表 pt(x) 只是多了一个同类的 object,此时只需要更新 pt(this),并不需要重新进行参数和返回值的连边。
此处不再赘述算法的细节和流程,这部分请看讲义和网课视频。
划重点
- 理解 PTA 的 rules
- 理解 PFG
- 理解 PTA 的算法
- 理解带 method call 的 PTA rules
- 理解过程间 PTA 的算法
- 理解 on-the-fly call graph 的构建
2021 考点
- 给定一段不含过程调用的程序,进行人工 PTA,画出 PFG 和各指针的 point-to set。
Trivia: Additional Rules
这些是在第五次实验手册里给出的 rules,大家可以阅读实验手册,推断如何实现它们。
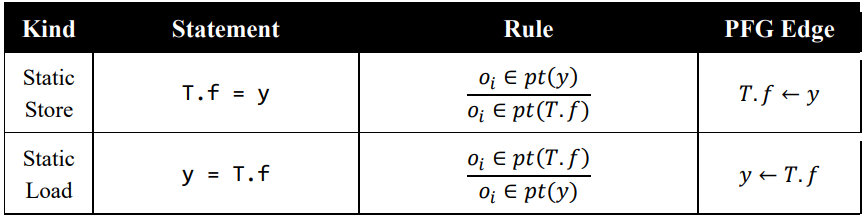
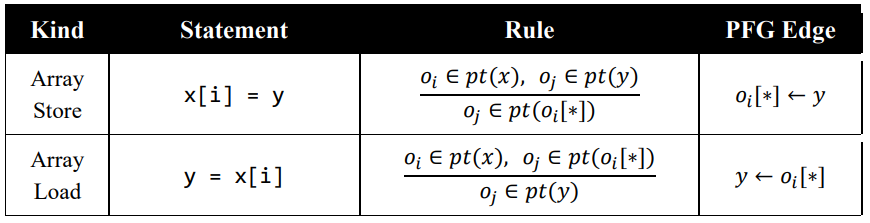

这部分的讲解在本仓库《手册的手册》部分有所介绍,欢迎阅读。